Jun 19, 2026 | PPC
Stran povzema povprečne stroške spletnega oglaševanja v ZDA v letu 2026 po glavnih kanalih in nato poda praktične ukrepe za znižanje stroškov ter izboljšanje učinkovitosti kampanj.

VIR: https://www.wordstream.com/blog/online-advertising-costs
-
Članek razlaga, da stroški spletnih oglasov skozi čas praviloma rastejo, hkrati pa se je na nekaterih platformah izboljšala učinkovitost, na primer prek višjih CTR in konverzij.
-
Glavni namen vodiča je postaviti realna pričakovanja glede proračuna za oglase glede na kanal, industrijo in poslovni cilj.
-
Google Ads je predstavljen kot kanal z visokim nakupnim namenom, vendar z relativno višjimi stroški na klik in na lead kot večina družbenih omrežij.
-
Družbena omrežja, zlasti Facebook, Instagram, TikTok, LinkedIn in YouTube, imajo zelo različne cenovne modele, zato mora izbira kanala slediti cilju kampanje.
-
Zadnji del članka poudarja, da stroškov ne obvladuje samo višina ponudbe, temveč predvsem relevantnost oglasa, ciljanje, remarketing in kakovost pristajalne strani.
-
Povprečna mesečna poraba malega podjetja za Google Ads je približno 3.000 USD ali več.
-
Povprečni CPC v Google Ads znaša 5,42 USD, povprečni CPL pa 66,69 USD.
-
Povprečni CPC pri Facebook traffic kampanjah znaša 0,70 USD, povprečni CPL pri lead kampanjah pa 27,66 USD.
-
Instagram CPC je ocenjen med 0,40 in 2 USD, TikTok CPV med 0,01 in 0,07 USD, LinkedIn CPC pa med 5 in 10 USD.
-
YouTube CPM je naveden med 4 in 10 USD, Google Display Network CPM pa med 3 in 10 USD.





Jun 17, 2026 | SEO
VIR: https://www.searchenginejournal.com/google-search-sends-23-of-queries-to-the-open-web/578724/
BISTVO
-
Članek povzema novo analizo SparkToro na podlagi podatkov Similarweb in ugotavlja, da se večina iskanj v Googlu zaključi brez obiska zunanje strani.
-
Osrednja teza je, da Google vse več odgovorov zadrži znotraj lastnega ekosistema, zato manj uporabnikov klikne na odprti splet.
-
Avtor navaja, da je glavni razlog za ta premik predvsem širjenje AI Overviews in drugih odgovorov neposredno v rezultatih iskanja.
-
Besedilo opozarja, da klasični SEO ostaja pomemben, vendar vse manj zanesljivo prinaša promet v obliki klikov.
-
Članek hkrati poudari metodološko omejitev: primerjava med leti ni popolnoma enotna, ker so bili uporabljeni različni podatkovni paneli.
DEJSTVA
-
Na vsakih 1.000 iskanj v Googlu v ZDA naj bi odprti splet prejel 232 klikov.
-
Med januarjem in aprilom naj bi se 68% ameriških iskanj končalo brez klika.
-
Razčlenitev vedenja po iskanju je naslednja: 39% brez nadaljnjega dejanja, 29% vodi v novo iskanje, 32% pa povzroči klik.
-
Od vseh klikov jih 66% vodi na odprti splet, 27% na Googlove oziroma Alphabetove površine, 6% pa na plačane oglase.
-
Delež iskanj, ki ustvarijo vsaj en klik, je po članku padel z 41% v letu 2024 na 32% v letu 2026, kar predstavlja 9,51 odstotne točke oziroma 22% relativnega padca.
CITATI
-
Rand Fishkin glede SEO zapiše: “it just won’t earn you traffic the way it once did.”
-
Liz Reid naj bi po navedbah članka dejala, da je organski obseg klikov “relatively stable”.
-
Reid naj bi še trdila, da AI Overviews večinoma odstranijo “bounce clicks”.
-
Fishkin metodološko primerjavo med leti opiše kot “a bit of apples and oranges.”
-
Članek navaja, da je AI Mode za zdaj “the variable to watch,” ker je v obravnavanem naboru predstavljal majhen delež, vendar naj bi njegova uporaba hitro rasla.
Jun 16, 2026 | LLM (AI)
Akt o umetni inteligenci EU uvaja prvi celovit, na tveganju temelječ pravni okvir za umetno inteligenco z različnimi obveznostmi glede na stopnjo tveganja.
VIR: https://digital-strategy.ec.europa.eu/sl/policies/regulatory-framework-ai
https://eur-lex.europa.eu/legal-content/SL/TXT/HTML/?uri=OJ:L_202401689
BISTVO:
-
Akt o umetni inteligenci je prvi celovit pravni okvir za umetno inteligenco na svetu in je v EU zasnovan za varnost, temeljne pravice ter zaupanja vredno uporabo AI.
-
Ureditev temelji na štirih ravneh tveganja: nesprejemljivo tveganje, visoko tveganje, tveganje za preglednost ter minimalno ali brez tveganja.
-
Prakse z nesprejemljivim tveganjem so prepovedane, med njimi socialno točkovanje, določene biometrične uporabe, prepoznavanje čustev na delovnih mestih ter množično zbiranje obraznih podatkov.
-
Sistemi z visokim tveganjem morajo pred vstopom na trg izpolniti zahteve glede ocene tveganj, kakovosti podatkov, sledljivosti, dokumentacije, človeškega nadzora, robustnosti in kibernetske varnosti.
-
Generativna umetna inteligenca in drugi sistemi s potrebo po preglednosti morajo uporabnike obveščati o uporabi AI ter omogočiti prepoznavanje AI-vsebin, zlasti pri globokih ponaredkih in javno relevantnih vsebinah.
DEJSTVA:
-
Akt je povezan z uradnim pravnim sklicem Uredba (EU) 2024/1689.
-
Akt opredeljuje 4 ravni tveganja za umetnointeligenčne sisteme.
-
Med prepovedanimi praksami je navedenih 8 kategorij nesprejemljive uporabe.
-
Prepovedi za nesprejemljive prakse so začele veljati februarja 2025, pravila za modele splošnega namena avgusta 2025, pravila o preglednosti pa začnejo veljati avgusta 2026.
Jun 10, 2026 | LLM (AI), Reference
Sistemska kartica predstavlja modela Claude Fable 5 in Claude Mythos 5, pri čemer je Mythos 5 zmogljivejša in manj omejena različica za zaupanja vredne partnerje, Fable 5 pa splošno dostopna različica z dodatnimi varovalkami za biologijo, kemijo in kibernetsko varnost.

BISTVO
-
Dokument je sistemska kartica z datumom 9. junij 2026 in opisuje dve konfiguraciji istega novega velikega jezikovnega modela podjetja Anthropic.
-
Claude Mythos 5 je po navedbah dokumenta najbolj zmogljiv model, ki ga je Anthropic doslej treniral, vendar je dostopen le majhnemu krogu preverjenih partnerjev, začetno v okviru Project Glasswing.
-
Claude Fable 5 uporablja iste osnovne uteži modela kot Mythos 5, vendar vključuje dodatne klasifikatorje in preusmeritve, ki omejujejo uporabo v tveganih domenah, zlasti v kibernetski varnosti ter biologiji in kemiji.
-
Glavni poudarki dokumenta so ocene po Responsible Scaling Policy, kibernetske zmogljivosti, varovalke in neškodljivost, agentska varnost, poravnava, dobrobit modela ter splošne zmogljivosti.
-
Splošna ocena dokumenta je, da so katastrofalna tveganja po mnenju Anthropic še vedno nizka, vendar so pri Mythos 5 višja kot pri prejšnjih modelih, zlasti na področju biologije, kemije in kibernetskih zmogljivosti.
DEJSTVA
-
Dokument navaja, da je Fable 5 za splošni dostop, Mythos 5 pa za omejeno uporabo pri preverjenih partnerjih.
-
Pri kemično-bioloških tveganjih Anthropic model Mythos 5 obravnava kot model s sposobnostmi ravni “CB-1”, vendar ne kot model, ki bi presegel prag “CB-2”.
-
V razdelku o biologiji dokument navaja, da sta dve od treh ekip splošnih biologov v eni oceni presegli vse tri ekipe specialistov, ko so uporabljale Mythos 5.
-
Ocenjevalci so zapisali, da bi naloge, za katere so ekipe z Mythos 5 potrebovale 16 ur, brez AI-orodij trajale od 40 do 95 delovnih dni, v povprečju 72,5 dneva.
-
Pri avtomatiziranih viroloških nalogah je Mythos 5 dosegel končni oceni 0,77 in 0,91, pri multimodalni virologiji pa 0,56, kar je nad ekspertno osnovo 0,221.
Jun 3, 2026 | Reference
Vzemite naslednji tekst in ga prilepite v katerikolii AI checker:
“Finally, my brethren, be strong in the Lord and in the power of His might. Put on the whole armor of God, that you may be able to stand against the wiles of the devil. For we do not wrestle against flesh and blood, but against principalities, against powers, against the rulers of the darkness of this age, against spiritual hosts of wickedness in the heavenly places.”
vir: https://www.biblegateway.com/passage/?search=Ephesians%206%3A10-12&version=KJV

Rezultat:

Jun 3, 2026 | SEO
Google uvaja prve meritve in nadzor za prikaz vsebin v AI odgovorih znotraj Search Console, vendar za zdaj omejeno na del lastnikov spletnih mest v Združenem kraljestvu in brez podatkov o klikih.
BISTVO
-
Google v Search Console uvaja novo poročilo za generativne AI funkcije iskanja, ki prikazuje vidnost strani v AI Mode, AI Overviews in sorodnih AI odgovorih.
-
Poročilo vključuje prikaze, strani, države, naprave in časovne razpone, vendar trenutno ne vključuje podatkov o klikih iz AI odgovorov na spletna mesta.
-
Poleg poročanja Google preizkuša tudi novo stikalo, s katerim lahko lastniki spletnih mest blokirajo uporabo svoje vsebine v AI funkcijah iskanja.
-
Google navaja, da izklop prikaza v AI funkcijah ne bi smel vplivati na uvrstitve v običajnih rezultatih spletnega iskanja.
-
Uvedba je za zdaj omejena na del uporabnikov v Združenem kraljestvu, ker je sprememba povezana tudi z regulatornimi zahtevami in pritiskom založnikov glede nadzora nad uporabo vsebin za AI.
DEJSTVA
- Novo AI poročilo v Search Console trenutno prikazuje pet glavnih dimenzij oziroma metrik: impressions, pages, countries, devices in dates.
-
Google navaja, da so podatki o času na voljo z urno, dnevno, tedensko in mesečno granularnostjo.
-
Članek omenja zgodnejšo raziskavo, po kateri bi približno ena tretjina SEO strokovnjakov blokirala uporabo vsebin v Googlovih AI iskalnih funkcijah.
CITATI
-
Google je zapisal: “We’re also starting to roll out new insights for website owners in Search Console about the appearance of their pages in generative AI Search features.”
-
O možnih prihodnjih metrikah je Googlov predstavnik povedal: “We’re continuing to work with website owners to understand what insights will be most helpful to inform their strategies, and we’ll introduce additional metrics over time.”
-
Google glede novega stikala piše, da lahko “website owners can decide if they want their site to appear in and help ground responses in our generative AI Search features.”
-
Google opozarja: “sites that opt out will not receive traffic or impressions from our generative AI features.”
-
Britanski CMA je navedel: “Google will now also have to allow publishers to opt-out of allowing their content to be used for the ‘fine-tuning’ of AI models.”
Pomen za lastnike spletnih mest
-
Glavna praktična novost je, da bodo založniki prvič dobili vsaj osnovni vpogled v to, kje se njihove strani pojavljajo v Googlovih AI odgovorih, čeprav brez ključnega podatka o dejanskem prometu prek klikov.
-
Še pomembnejša je možnost nadzora: če bo stikalo uvedeno širše, bodo lahko lastniki spletnih mest ločeno odločali o prisotnosti v AI funkcijah, ne da bi morali tvegati slabšo organsko vidnost v klasičnem iskanju.
-
Za SEO in založniške ekipe to pomeni nov operativni okvir: spremljanje AI prikazov, ocenjevanje koristi vidnosti brez klikov in odločanje, ali je vključitev v AI funkcije poslovno smiselna.
Jun 3, 2026 | LLM (AI)
Microsoft je predstavil Web IQ kot nov “grounding” API za dobo agentov, zgrajen na Bingovem indeksu, vendar optimiziran za način iskanja, ki ga uporabljajo AI-agentni sistemi, ne ljudje.
BISTVO
-
Članek pojasnjuje, da je Web IQ Microsoftova nova zbirka AI-native API-jev, ki agentom omogoča dostop do svežih podatkov s spleta, novic, slik in videov.
-
Ključna ideja je, da AI-agenti ne iščejo kot ljudje, saj ne opravijo le ene poizvedbe, ampak izvajajo večstopenjsko, razvejano iskanje in iz dokumentov izluščijo točno potrebne informacije.
-
Microsoft navaja, da je zato sistem preoblikoval od indeksiranja in pridobivanja podatkov do razvrščanja, izbire odlomkov in orkestracije, da bolje podpira “inference-time grounding”.
-
Članek poudarja tudi stroškovno učinkovitost: manj vhodnih tokenov naj bi pomenilo boljše odgovore in nižji strošek na klic.
-
Za SEO in spletne lastnike je glavno sporočilo, da se splet prilagaja agentnim izkušnjam, zato bodo morale tudi spletne strani postati bolj primerne za branje, razumevanje in uporabo s strani AI-agentov.
DEJSTVA
- Web IQ že uporablja Microsoft v Copilotu, uporablja pa ga tudi OpenAI za nekatere odgovore v ChatGPT.
-
Microsoft trdi, da je Web IQ približno 2,5-krat hitrejši od naslednje najboljše alternative.
-
Dostop je trenutno omejen predvsem na Microsoftove in večje LLM-platforme, Microsoft pa navaja, da bo dostop širil postopoma ter interesente usmerja na spletno stran webiq.microsoft.ai.
Jun 3, 2026 | PPC
Microsoft interno priznava učinek AI-povzetkov na manj klikov in manj obiskov spletnih strani, kar je v nasprotju z javnimi stališči Googla.

VIR
BISTVO
-
Članek na Search Engine Roundtable poroča o predstavitvi Jamesa Murrayja iz Microsofta z naslovom How to successfully navigate the human, LLM, and agentic web, kjer se je na diapozitivu pojavila trditev: »AI summarizes results, reducing clicks and website visits.«
-
Avtor Barry Schwartz izpostavi, da Microsoftov diapozitiv neposredno priznava, da AI-povzetki zmanjšujejo klike in promet na spletna mesta.
-
Osrednja poanta članka je kontrast med Microsoftovo formulacijo in Googlovimi prejšnjimi izjavami, da so kliki pri AI-pregledih razmeroma stabilni.
Jun 1, 2026 | PPC
Članek pojasnjuje, da cena Google Ads nima enotnega odgovora, ampak je odvisna predvsem od panoge, konkurence ključnih besed, kakovosti oglasov, ciljanja in načina upravljanja računa. Glavna uporabna orientacija je, da je povprečni CPC na Search omrežju v letu 2026 5,42 USD, povprečni CPL 66,69 USD, začetni SMB proračun pa pogosto 1.000–2.500 USD mesečno oziroma približno 20–50 USD na dan za nove kampanje.




BISTVO
-
Članek pojasni, da na vprašanje “koliko stane Google Ads” ni univerzalnega odgovora, saj se cena razlikuje glede na panogo, nakupni cikel kupca, aktualne trende in kakovost upravljanja kampanj.
-
Osnovni referenčni podatek za leto 2026 je povprečni CPC na Google Search 5,42 USD, medtem ko so kliki na Display omrežju praviloma cenejši in pogosto pod 1 USD.
-
Avtorica poudari, da Google Ads deluje kot dražbeni sistem, kjer ni odločilna samo ponudba, temveč tudi Quality Score, zato lahko boljši oglas doseže višjo pozicijo z nižjim dejanskim stroškom klika.
-
Članek jasno loči med pojmi budget, bid, spend in cost ter opozori, da dnevni proračun ni trda dnevna omejitev, ampak povprečna ciljna poraba skozi mesec.
-
Poleg samega oglasnega proračuna morajo podjetja upoštevati še stroške agencijskega upravljanja, izgubljeno porabo in potrebo po stalni optimizaciji, kot so negativne ključne besede, geotargeting in urniki prikazovanja.
DEJSTVA
-
Avtorica članka je Kristen McCormick, članek pa je bil nazadnje posodobljen 1. junija 2026.
-
Povprečni cost per lead v Google Ads v letu 2026 znaša 66,69 USD.
-
Povprečni začetni mesečni proračun za mala in srednja podjetja je naveden v razponu 1.000–2.500 USD, nove kampanje pa pogosto stanejo približno 20–50 USD na dan.
-
Povprečen Google Ads račun porabi 3.127,38 USD mesečno; v analizi več kot 15.000 računov jih 24% porabi manj kot 1.000 USD na mesec, 39% med 1.000 in 10.000 USD, 37% pa več kot 10.000 USD.
-
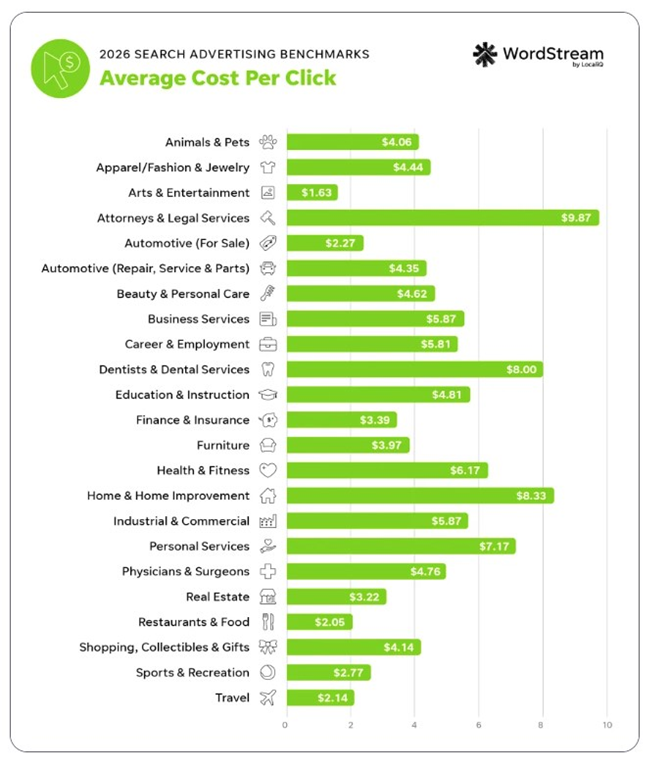
Med najdražjimi panogami po CPC so Attorneys & Legal Services z 9,87 USD, Home & Home Improvement z 8,33 USD, Dentists & Dental Services z 8,00 USD, Personal Services s 7,17 USD in Health & Fitness s 6,17 USD.
CITATI
-
“The clearest (and most infuriating) one I can provide is: it depends.”
-
“The average cost per click in Google Ads in 2026 was $5.42.”
-
“The average cost per lead in Google Ads in 2026 was $66.69.”
-
“The average Google Ads account spends $3,127.38 per month.”
-
“The average Google Ads account sees $1,127.54 in wasted spend per month.”


















{kind=link}