Apr 21, 2026 | SEO
„4 SEO koncepti, ki vam ne pomagajo” — avtor Mike Friedman razgrinja štiri pogosto napačno razumljene SEO prakse, ki po nepotrebnem jemljejo čas in energijo.
VIR: https://theseopub.com/4-seo-concepts-that-arent-helping-you/

BISTVO — 5 ključnih ugotovitev:
-
Google že dolgo ne temelji na štetju ključnih besed, temveč razume entitete, kontekst in namen iskanja, zato optimizacija gostote ključnih besed ni smiselna
-
Ocena PageSpeed Insights (Lighthouse) je laboratorijsko orodje za diagnostiko napak, ne merilo za rangiranje — Google dejansko uporablja podatke iz resničnih uporabniških sej (Core Web Vitals)
-
Daljša vsebina ne rangira bolje sama po sebi; rangira bolje, ker pogosto pokriva več entitet in odgovori na več vprašanj — a besedna dolžina brez vsebinske vrednosti ne pomaga
-
Orodja tretjih strani, ki označujejo “toksične” povezave, pogosto niso usklajena z Googlovimi dejanskimi kriteriji; Google v večini primerov sam ignorira nizkokakovostne povezave
-
Skupni vzorec napak je, da se optimizatorji osredotočijo na konkretne, merljive številke namesto na dejavnike, ki dejansko vplivajo na to, kako Google ocenjuje stran
DEJSTVA — 5 podatkovnih dejstev:
-
Lighthouse oceni tri Core Web Vitals metrike: LCP (hitrost nalaganja največjega elementa), INP (odzivnost na interakcijo) in CLS (nestabilnost postavitve)
-
Stran z oceno 65 v Lighthouse ima lahko odlične Core Web Vitals, stran z oceno 98 pa slabe — ker laboratorijsko in terensko merjenje nista enaka
-
Primer: stran z 3.000 besedami polnila se obnese slabše od strani z 1.200 besedami globinskega znanja
-
Orodje za disavow je namenjeno izrecno dvema primeroma: manualnim kaznim in zavestni udeležbi v shemah plačanih povezav
-
Avtor je Mike Friedman, članek je bil objavljen 21. aprila 2026
CITATI — 5 dobesednih citatov:
-
“There is no target percentage. There hasn’t been one for a very long time.” — o gostoti ključnih besed
-
“The Lighthouse score you see in PageSpeed Insights is a lab-based diagnostic tool… It’s a debugging tool.”
-
“More words is not more information gain. More novel, specific information is more information gain.”
-
“Google has said repeatedly that its algorithms are very good at identifying and ignoring low-quality links on their own.”
-
“The fix is always the same question. Does this thing I’m spending time on directly influence how Google evaluates my site?”
Apr 21, 2026 | SEO
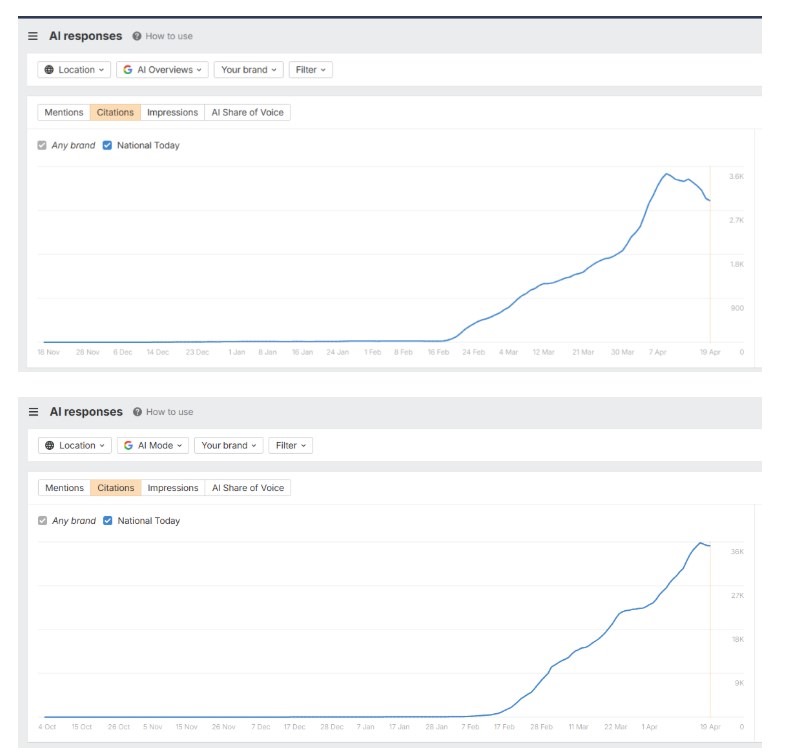
Članek opozarja na sistemsko tveganje: agresivno in nepremišljeno skaliranje z AI-vsebino za SEO ne prinaša le Google kazni (v tem primeru ročne, sicer pa v obliki padca v serp-u – praviloma kmalu po začetnem vrhu), temveč se posledice kaskadno razširijo na vse AI iskalne platforme, ki temeljijo na Googlovem indeksu. Primer NationalToday.com je jasen dokaz, da »Mt. AI« strategije delujejo le začasno, nato pa se sesuljejo na vseh frontah hkrati.
BISTVO
-
Spletišče NationalToday.com je v direktoriju /us/ objavilo več kot 850.000 100% AI-generiranih lokalnih novic, ki so se uvrščale v Google Top Stories, News in Discover
-
Google je po razkritju portala Futurism izdal ročni ukrep za »scaled content abuse« in celoten direktorij odstranil iz indeksa
-
Odstranitev iz Googlovega indeksa je neposredno povzročila izpad v AI Overviews, AI Mode in posledično v ChatGPT citatih
-
ChatGPT pri iskanju z utemeljitvijo na spletu delno uporablja Googlov indeks, zato spletišče, ki je odstranjeno iz Googla, izgubi tudi večino CitGPT citatov
-
Izjema so redki primeri, kjer ChatGPT za utemeljitev uporablja Bing ali drug vir in citati ostanejo
DEJSTVA
-
850.000+ URL-jev v /us/ direktoriju — vse 100% AI-generirane vsebine
-
Vidnost spletišča se je po ročnem ukrepu takoj strmoglavila — tipičen vzorec, ki ga Gabe imenuje »Mt. AI«
-
Preverjanje je potekalo na več ChatGPT računih (plačljivi in brezplačni) prek orodja Brand Radar (Ahrefs)
-
Večina citatov za /us/ direktorij je izginila; le redki so ostali (verjetno prek Bing indeksa)
-
Ukrep je prizadel izključno /us/ direktorij — preostala vsebina NationalToday.com v Googlu in ChatGPT-u ostaja nedotaknjena
CITATI
-
“A recent manual action provides a great view of how scaling via AI-generated content can yield a huge drop in Google’s 10-blue links, AI Overviews, and AI Mode.”
-
“When ChatGPT searches the web to ground answers, it can leverage Google’s index (which has been documented many times).”
-
“If you receive a manual action from Google… then you will drop in AIOs, AI Mode, and then downstream in AI search (which includes ChatGPT).”
-
“Do not implement risky and spammy tactics just to rank in AI search.”
-
“It works until it doesn’t. It’s just another example of ‘Mt. AI’. Beware.”
Apr 16, 2026 | SEO
vir: https://growtika.com/blog/tech-media-collapse

tudi v netehnoloških medijih je kot kaže podobno:

BISTVO
-
Organski obisk desetih največjih angleškojezičnih tehnoloških publikacij se je od vrhunca leta 2024 do januarja 2026 zmanjšal za približno 58%.
-
Skupni vrh organskega prometa teh medijev je bil 112 milijonov obiskov, januarja 2026 pa le še 47 milijonov, kar pomeni izgubo 65 milijonov obiskov.
-
Večina analiziranih medijev je zabeležila vsaj 50‑odstotni padec, pri čemer je The Verge izgubil približno 85% organskega prometa.
-
Avtorji analize kot možne razloge navajajo uvedbo Google AI Overviews, dvig Reddita v iskalnih rezultatih ter razmah generativnih iskalnih chatbotov (ChatGPT, Claude, Perplexity).
-
Članek problematizira vzdržnost prihodkovnih modelov, ki so izrazito odvisni od prometa iz iskalnikov, in opozarja na neposredno povezavo med padcem prometa in padcem prihodkov.
DEJSTVA
-
Analiza temelji na ocenah organskega prometa v ZDA za 10 velikih tehnoloških publikacij (npr. Wired, CNET, Mashable, The Verge, PCMag), pridobljenih z orodjem Ahrefs.
-
Skupni vrh prometa je bil 112 milijonov organskih obiskov v letu 2024, januarja 2026 pa 47 milijonov, kar pomeni približno 58‑odstotni padec.
-
The Verge je padel z več kot 5,3 milijona organskih obiskov (februar 2024) na približno 790.000 (januar 2026), kar je približno 85‑odstotni padec.
-
CNET in PCMag sta utrpela 47‑ oziroma 41‑odstotni padec prometa, Mashable pa “najmanjši” padec, okoli 30% (z 16,1 na 11,3 milijona obiskov).
-
Analiza poudari, da uporablja ocenjene podatke Ahrefs in da primerjava “vrhunca 2024” z januarjem 2026 verjetno delno poveča dramatičnost upada.
r
Apr 13, 2026 | LLM (AI), SEO
VIR
https://www.link-assistant.com/news/how-google-detects-ai.html
BISTVO
-
Google DeepMind je razvil SynthID, neviden vodni žig, ki se vgradi v AI-generirano besedilo, slike, video in zvok ter omogoča zanesljivo strojno zaznavo izvora vsebine.
-
Vodni žig ni v metapodatkih, temveč v sami vsebini, zato preživi običajne obdelave (obrezovanje, kompresija, zaslonski posnetki, blagi filtri) in se ga z “casual” urejanjem ne da odstraniti.
-
Glavni motiv za zaznavanje AI ni neposredno kaznovanje v iskanju, temveč preprečevanje “model collapse” – degradacije prihodnjih modelov, ko se ti učijo na AI-izpisih namesto na človeških podatkih.
-
Za SEO je ključno uporabljati AI za raziskavo, osnutke in pospešitev dela, nato pa v vsebino vgraditi lastne podatke, izkušnje in specifične vpoglede, ki jih AI ne more ponoviti.
-
Spletni založniki lahko tehnično zmanjšujejo zaznavnost vodnih žigov (močno prepisovanje, prevajanje, regeneracija z drugimi modeli), vendar to ne rešuje bistva: ali je vsebina dovolj uporabna, citabilna in vredna povezav.
DEJSTVA
-
Google poroča, da je bilo v začetku 2026 z SynthID označenih že več kot 10 milijard kosov vsebine v njihovih AI-orodjih (Gemini, Imagen, Lyria, Veo).
-
V koaliciji C2PA za standard “Content Credentials” sodeluje več kot 200 organizacij, med drugim Microsoft, Adobe, OpenAI, Meta, BBC in Amazon.
-
Raziskava v reviji Nature kaže, da treniranje modelov pretežno na AI-generiranih podatkih vodi v degenerativni učinek (model collapse), kjer se izhodi postopno odmikajo od realnosti.
-
Študija princetonskih raziskovalcev ugotavlja, da dodajanje statistik in citiranih virov lahko poveča “AI citation rate” vsebine za približno 30–40%.
-
Test 14 komercialnih AI-detektorjev leta 2023 ni pokazal niti enega orodja z vsaj 80% natančnostjo, pri čemer so nekateri pogosto označili človeško besedilo kot AI.
CITATI
-
“SynthID is a watermarking technology developed by Google DeepMind. It embeds an invisible digital watermark into AI-generated content.”
-
“The watermark isn’t stored in removable metadata — it’s embedded in the content itself.”
-
“AI models learn from data scraped from the internet. As more and more of that internet gets filled with AI-generated content, future models increasingly end up training on AI outputs rather than human writing.”
-
“Stop using AI for content entirely? No. That’s not the takeaway.”
-
“Passing a detector and being worth citing are two different problems, and the second one is harder to game.”
Mar 25, 2026 | Ecommerce, SEO

Kaj je UCP in zakaj je pomemben
-
Google Universal Commerce Protocol (UCP) je standardiziran način, da AI interakcije (Search, AI Mode, Gemini) pretvori v dejanski nakup brez obiska spletne trgovine.
-
UCP omogoča, da AI vmesnik prikaže izdelke, zgradi košarico in izvede plačilo (Google Pay, Shop Pay, PayPal, Stripe, kasneje tudi kripto) prek varnih, tokeniziranih plačilnih strežnikov trgovcev.
-
Trenutno je na voljo za ameriške trgovce z vsaj približno 50 izdelki in zahteva vzpostavljen Google Merchant Center za pravilno serviranje kataloga.
Poslovni agenti in nova “SEO disciplina”
-
Google uvaja poslovne agente, tj. AI pomočnike, ki predstavljajo podjetje neposredno v iskalnih rezultatih in v Gemini, z logotipom, barvami in prilagojenimi “welcome” sporočili.
-
Agent črpa podatke iz Merchant Centerja in spletnega mesta, zato je ključno, da so pogosta vprašanja in ključne informacije jasno zapisane na strani; sicer lahko agent halucinira napačne odgovore.
-
Avtorica svetuje, da podjetja z lansiranjem agentov še nekoliko počakajo, dokler ne bo več nadzora nad treningom (brand guidelines, size guide, primeri odgovorov) in vpogledom v pogovore ter metrike uspešnosti.
Kako UCP deluje tehnično (AP2, mandati, varnost)
-
Jedro plačil je Agent Payments Protocol (AP2), ki uporablja kriptografsko podpisane verifiable credentials (VC) namesto klasičnih API klicev.
-
Uporabljajo se trije tipi mandatov:
-
cart mandate (človeški prisoten nakup, podpisana konkretna košarica, cena, dostava),
-
intent mandate (človeški ne‑prisoten scenariji tipa “kupi karte, ko gredo ob polnoči v prodajo” s pogoji, npr. max cena),
-
payment mandate (poseben credential za plačilno omrežje in banke, označi, da je sodeloval AI agent).
-
Tok pri human‑present nakupu: trgovec podpiše košarico, uporabnik jo odobri in njegov device podpiše cart in payment mandate, nato se transakcija izvrši.
Kdo UCP že uporablja in odnos do drugih protokolov
-
UCP je že privzeto vključen pri Shopify trgovcih; njihovi izdelki se “avtomatsko” sindicirajo v AI servise.
-
Protokol sprejemajo tudi Etsy, Wayfair, Best Buy, Visa, American Express, Mastercard, Home Depot in Walmart, pri čemer Walmart preizkuša precej agresivne scenarije z AI agenti in dostavo.
-
UCP ni vezan samo na Google – podobno kot HTTP je zamišljen kot univerzalen standard, ki bo deloval tudi v Copilotu, ChatGPT in drugod, medtem ko je OpenAI‑jev ACP bolj osredotočen na instant checkout v ChatGPT ekosistemu.
Vpliv na e‑commerce, uporabnike in prihodnost
-
Za uporabnike je glavna prednost ekstremno hiter, “frictionless” nakup: pogovor z AI (v brskalniku, očalih, pametnem domu), klik ali glasovno dovoljenje in nakup je izveden brez obiskovanja strani in izpolnjevanja obrazcev.
-
Varovalke proti zlorabam temeljijo na omenjenih mandatih, omejitvah (cene, kategorije) in kriptografski nedvoumni avtorizaciji.
-
Za trgovce je največja skrb izguba nadzora nad “customer journeyjem” in neposrednim odnosom, saj bo del občinstva popolnoma preskočil spletno mesto, a avtorica meni, da bodo vsaj nekaj let ljudje še vedno tudi brskali po klasičnih straneh.
-
V prihodnjih letih Google napoveduje podporo za multi‑item checkout, kompleksna pravila košarice, upsell in bolj napredne scenarije, kar bo dodatno standardiziralo uporabo UCP v večini večjih platform.
-
Video povezuje UCP z širšo vizijo: AI očala, glasovno naročanje prek Google Home, dronska dostava (Google + Walmart Wing), in dolgoročno celo fizični roboti (partnerstvo z Boston Dynamics), ki agentično kupujejo in izvajajo opravila za uporabnika.







{kind=link}